
Fonte: https://concani3.wordpress.com/2013/10/27/analise-de-desempenho-de-uma-maquina-linux-com-debian/
Introdução
1.1 Pontos fundamentais a analisar no sistema
Existem quatro recursos que têm grande impacto sobre o desempenho da máquina e entendemos serem obrigatórios seu monitoramento:
Existem diversas ferramentas livres úteis para fazer análises de uma máquina com Linux. Listarei abaixo algumas destas ferramentas que utilizo com mais frequência.
Dados relevantes para isto: utilização global da CPU, médias de cargas e consumo de CPU por processo.
2.1 Ferramenta vmstat
vmstat – virtual memory statistics, reporta informações sobre processos, memória, paginação, blocos de IO, interrupções, discos e atividade da CPU.
Exemplos:
procs – r: número de processos esperando para serem executados na fila de execução (esperando por “run time”).
procs – b: número de processos em uninterruptible sleep (“busy processes”).
Swap – so: memória “swapped” para o disco (a cada segundo)
IO – bi: blocos recebidos do disco (blocks/s – cada bloco é de 1024 bytes). OBS: é a mesma informação dada em “kB_read/s” da ferramenta “iostat”.
IO – bo: blocos enviados para o disco (blocks/s). OBS: é a mesma informação dada em “kB_wrtn/s ” da ferramenta “iostat”.
System – in: número de interrupções por segundo (incluindo o clock).
System – cs: número de trocas de contexto por segundo (quando a CPU chaveia de um processo (ou “thread”) para um outro, isto é chamado de troca de contexto).
CPU – us: % do total de CPU time gasto executando código non-kernel. (user time, including nice time)
CPU – sy: % do total de CPU time gasto executando código do kernel. (system time, na prática serve para o processamento de eventos do sistema.)
CPU – id: % do total de CPU time idle (inatividade).
CPU – wa: % do total de CPU time gasto esperando por IO
2.2 Ferramenta mpstat
mpstat é um software de linha de comando de computador utilizado em sistemas operacionais do tipo Unix para relatar (na tela) estatísticas relacionadas ao processador. Ele é usado na monitorização de computador a fim de diagnosticar problemas ou para construir estatísticas sobre o uso da CPU. A primeira CPU é identificada pelo número “0”.
Sintaxe:
Exemplos:
Informa em uma linha as seguintes informações: hora atual, a quanto tempo o sistema está funcionando, quantos usuários estão conectados, e as médias de carga do sistema nos últimos 1, 5 e 15 minutos. Estas são as mesmas informações contidas na linha do cabeçalho exibido pelo comando “w”.
# uptime
14:42:12 up 4 days, 8:28, 1 user, load average: 1,15, 1,29, 1,33
ps: relatório instantâneo dos processos atuais.
top: um “ps” repetitivo
Ferramentas como o ‘ps’ e ‘top’ relatam vários tipos de usos de memória, tais como o tamanho da VM e o “Resident Set Size (RSS)”. No entanto, nenhum deles informa realmente o uso da memória “real”:
Exemplos:
VSZ – virtual set size (em KB, quanto de memória o processo estaria utilizando se ele fosse o único processo rodando, sem utilizar bibliotecas compartilhadas).
RSS – resident set size (em kB, indica – em tese – a quantidade de memória física que o processo está usando)
2.5 Ferramenta nmon
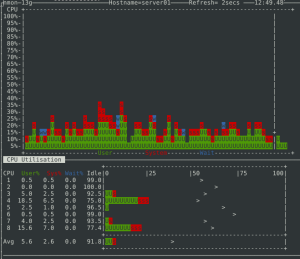
nmon é um administrador de sistemas, sintonizador, ferramenta de benchmark. Ele pode exibir o CPU, memória, rede, discos (mini gráficos ou números), sistemas de arquivos, NFS, os processos principais, recursos (versão do Linux e processadores) e outras informações. Ao iniciar o aplicativo, este fica esperando comandos do usuário, cuja lista pode ser visualizada através da telca “h”. Veja a ilustração abaixo:
3. Analisando a utilização da memória
O Linux gerencia a memória em unidades chamadas páginas. O tamanho atual de uma página de memória no PC é de 4K. O kernel do Linux aloca páginas virtuais para processos à medida que eles forem solicitando memória. O Linux pode alocar efetivamente tanta memória quanto os processos solicitarem amplicando a RAM real com espaço de swap.
Basicamente, três números quantificam a atividade de memória:
3.1 Indo direto a fonte de informação
Mostra a quantidade total de memória livre e utilizada no sistema, tanto a memória física como a de swap, bem como os buffers utilizados pelo kernel. A coluna de memória compartilhada (“shared memory”) deve ser ignorado, está obsoleta.
Exemplos:
Mostra o sumário do uso de swap por “device”.
Mostra estatisticas do sistema a partir de /proc. Algumas das informações na saíde de procinfo sobrepõem aquelas de free, uptime e vmstat.
Exemplos:
a) sobre o load average:
3/330 – existem 330 processos no total
26091 – último processo a ser executado tinha PID 26091
b) context – número de trocas de contexto, desde a inicialização.
c) page in – número de blocos do disco paginada do disco na RAM. Um bloco é igual a 1 KB.
d) page out – número de blocos de disco paginada da RAM para o disco. Isso inclui a escrita regular no disco.
e) Interrupções – número de interrupções desde o boot, ou por intervalo, listado por IRQ.
4. Analisando o I/O de disco
4.1 Ferramenta iostat
Relatório com estatísticas da CPU e de entrada/saída de dispositivos e partições. Usado para monitorar o sistema de carga de entrada/saída de dispositivos, observando o tempo que os dispositivos estão ativos em relação às suas taxas de transferências médias.
Exemplos:
a) tps – transações totais por segundos, que é a soma do número de transações de leitura por segundo com o número de transações de escrita por segundo.
b) kB_read/s – quantidade de dados lidos a partir do dispositivo, expressa em número de blocos (kilobytes) por segundo. Blocos são equivalentes aos setores e, portanto, têm um tamanho de 512 bytes. OBS: é a mesma informação dada em “IO – bi” da ferramenta vmstat.
c) kB_wrtn/s – quantidade de dados gravados no dispositivo expresso em número de blocos (kilobytes) por segundo. OBS: é a mesma informação dada em “IO – bo” da ferramenta vmstat.
d) kB_read – o total número de blocos (kilobytes) lidos.
e) kB_wrtn – o total número de blocos (kilobytes) escritos.
5. Análise de I/O de rede
5.1 Ferramenta IPTraf
IPTraf é um monitor de LAN IP que gera várias estatísticas de rede, incluindo informações TCP, contagens UDP, informações ICMP e OSPF, informações de carga Ethernet, estatísticas do “node”, erros de checksum IP entre outros. O aplicativo pode funcionar no modo interativo ou em background. Se o comando iptraf é emitido sem o parâmetro “-B” na sua linha de comando, o programa inicia no modo interativo, com as diversas facilidades acessados através do menu principal.
A forma mais simples de iniciar o aplicativo no modo interativo, basta usar o comando sem qualquer parâmetro:
Para o modo em background, é importante fazer previamente a configuração do IPTraf através do modo interativo, e só após isto iniciar a sessão de aquisição estatistica em background. Configure o aplicativo da maneira usual (definir os filtros, logs, intervalos de aquisição, adicionar as portas TCP/UDP, etc). Uma vez feito a configuração, elimine todas as instâncias do IPTraf que possam existir no sistema, e invoque o IPTraf da linha de comando com os parâmetros desejados, não esquecendo obrigatoriamente do parâmetro “-B” para criar o programa daemon.
Exemplos de comandos para IPTraf em background:
a) Monitorar o tráfego IP para a interface eth0, durante 3 minutos:
obs: cuidado, o arquivo de log poderá crescer muito se o tempo de coleta for grande!
b) Coletar estatísticas detalhadas da interface eth0, durante 5 minutos:
c) Coletar estatísticas sobre os serviços que estão sendo utilizados pela interface eth0, durante 2 minutos:
Obs:
1.1 Pontos fundamentais a analisar no sistema
Existem quatro recursos que têm grande impacto sobre o desempenho da máquina e entendemos serem obrigatórios seu monitoramento:
- tempo de CPU
- memória
- I/O de disco rígido
- I/O de rede
Existem diversas ferramentas livres úteis para fazer análises de uma máquina com Linux. Listarei abaixo algumas destas ferramentas que utilizo com mais frequência.
- vmstat (já instalado: hashed em /usr/bin/vmstat)
- uptime (já instalado: hashed em /usr/bin/uptime)
- nmon (apt-get install nmon)
- free (já instalado: hashed em /usr/bin/free)
- mpstat (apt-get install sysstat)
- procinfo(apt-get install sysstat)
- top (já instalado: /usr/bin/top)
- ps (já instalado: hashed em /bin/ps)
- IPTraf (apt-get install iptraf)
- Virtual memory = é a soma do espaço de swap disponível no disco + memória RAM física. A memória virtual abrange o espaço da aplicação e o espaço do kernel.
- A utilização de um sistema de 32-bit ou de 64-bit faz muita diferença na determinação do quanto de memoria um processo pode utilizar. Em um sistema de 32-bit um processo pode acessar apenas um máximo de 4GB de memória virtual. Em um sistema de 64-bit não existe tal limitação. A RAM não utilizada será usada como cache do sistema de arquivos pelo kernel.
- O sistema Linux fará swap quando ele necessitar de mais memória. Isto é, quando ele necessitar de mais memória que a memória física RAM. Quando ele faz o swap, ele escreve as páginas de memória menos acessadas da memória física RAM para o disco.
- Um número excessivo de “swapping” pode causar impactos negativos na performance do sistema, em função da velocidade do disco ser muito menor que da memória física além desta operação em si também tomar tempo na transferência de dados entre RAM-disco.
Dados relevantes para isto: utilização global da CPU, médias de cargas e consumo de CPU por processo.
2.1 Ferramenta vmstat
vmstat – virtual memory statistics, reporta informações sobre processos, memória, paginação, blocos de IO, interrupções, discos e atividade da CPU.
Exemplos:
# vmstat (médias desde o momento que o sistema fora inicializado)
# vmstat -s (mostra uma tabela com a síntese de varios contadores de eventos e estatísticas da memória)
# vmstat -d (informações estatisticas atividades do disco)
# vmstat -D (sumário das estatisticas sobre as atividades do disco)
# vmstat 5 10 (estes dois números representam: número segundos a observar/número de relatórios)
# vmstat 5 4
procs -----------memory------------ ---swap-- ----io-- --system- ----cpu----
r b swpd free buff cache si so bi bo in cs us sy id wa
1 0 0 14477472 140848 775312 0 0 0 47 2230 1321 14 6 80 0 (<-- as="" desde="" dias="" esta="" font="" fora="" inicializado="" linha="" m="" momento="" o="" primeira="" que="" s="" sempre="" sistema="">
0 0 0 14528584 140864 759252 0 0 0 112 2027 1231 14 5 81 0
0 0 0 14526948 140872 759084 0 0 1 106 2258 1239 13 5 82 0
0 0 0 14527120 140880 759328 0 0 4 106 2149 1526 16 7 77 0
procs – r: número de processos esperando para serem executados na fila de execução (esperando por “run time”).
procs – b: número de processos em uninterruptible sleep (“busy processes”).
OBS: a fila de execução indica o número total de processos ativos na fila corrente esperando por tempo de CPU. Quando a CPU está pronta para executar um processo, ela retira este processo da fila baseado nas prioridades dos processos. É importante destacar que os processos que estão no estado “sleep”, ou no estado esprando i/o não ficam na fila de execução.Swap – si: memória “swapped” do disco (a cada segundo)
Swap – so: memória “swapped” para o disco (a cada segundo)
IO – bi: blocos recebidos do disco (blocks/s – cada bloco é de 1024 bytes). OBS: é a mesma informação dada em “kB_read/s” da ferramenta “iostat”.
IO – bo: blocos enviados para o disco (blocks/s). OBS: é a mesma informação dada em “kB_wrtn/s ” da ferramenta “iostat”.
System – in: número de interrupções por segundo (incluindo o clock).
System – cs: número de trocas de contexto por segundo (quando a CPU chaveia de um processo (ou “thread”) para um outro, isto é chamado de troca de contexto).
CPU – us: % do total de CPU time gasto executando código non-kernel. (user time, including nice time)
CPU – sy: % do total de CPU time gasto executando código do kernel. (system time, na prática serve para o processamento de eventos do sistema.)
CPU – id: % do total de CPU time idle (inatividade).
CPU – wa: % do total de CPU time gasto esperando por IO
2.2 Ferramenta mpstat
mpstat é um software de linha de comando de computador utilizado em sistemas operacionais do tipo Unix para relatar (na tela) estatísticas relacionadas ao processador. Ele é usado na monitorização de computador a fim de diagnosticar problemas ou para construir estatísticas sobre o uso da CPU. A primeira CPU é identificada pelo número “0”.
Sintaxe:
# mpstat Exemplos:
# mpstat -A
# mpstat -u 3
# mpstat -P 0
# mpstat -P ALL
# mpstat -P 1,2
# mpstat -P ALL -u 10
# mpstat -I SCPU
# mpstat -I ALL
# mpstat -I ALL -u -P ALL
# mpstat -u 3
Linux 3.2.0-4-amd64 (server01.meusitio.org) 25-10-2013 _x86_64_ (8 CPU)
21:04:02 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %idle
21:04:05 all 12,03 0,00 5,51 0,25 0,00 0,04 0,00 0,00 82,16
21:04:08 all 9,60 0,00 3,42 0,38 0,00 0,08 0,00 0,00 86,51
21:04:11 all 6,34 0,00 1,84 0,00 0,00 0,00 0,00 0,00 91,82
21:04:14 all 15,78 0,00 4,67 0,29 0,00 0,00 0,00 0,00 79,26
21:04:17 all 13,73 0,00 6,05 0,00 0,00 0,13 0,00 0,00 80,10
21:04:20 all 13,93 0,00 5,97 0,25 0,00 0,08 0,00 0,00 79,77
21:04:23 all 8,84 0,00 3,05 0,29 0,00 0,00 0,00 0,00 87,82
- %usr percentual de utilização da CPU, que ocorreu durante a execução no nível de usuário (aplicação).
- %nice percentual de utilização da CPU, que ocorreu durante a execução no nível de usuário com prioridade “nice”.
- %sys percentual de utilização da CPU, que ocorreu durante a execução no nível do sistema (kernel). Note-se que esta não inclui o tempo gasto de assistência ao hardware nem de interrupções de software.
- %iowait percentual de tempo que a CPU ou CPUs estavam ociosas, durante o qual o sistema teve um pedido de I/O.
- %irq percentual de tempo gasto pela CPU ou CPUs para tratar interrupções de hardware.
- %soft percentual de tempo gasto pela CPU ou CPUs para atender interrupções de software.
- %idle percentual de tempo que a CPU ou CPUs estavam ociosas e o sistema não tinha um pedido de I/O de disco.
Informa em uma linha as seguintes informações: hora atual, a quanto tempo o sistema está funcionando, quantos usuários estão conectados, e as médias de carga do sistema nos últimos 1, 5 e 15 minutos. Estas são as mesmas informações contidas na linha do cabeçalho exibido pelo comando “w”.
# uptime
14:42:12 up 4 days, 8:28, 1 user, load average: 1,15, 1,29, 1,33
“load average”: hora atual/a quanto tempo o sistema está executando/quantos usuários estão correntemente logados/”load averages” do sistema do últimos 1, 5 e 15 minutos nesta ordem.2.4 Ferramentas: ps e top
OBS: system load averages:
a) O load average é calculado combinando o número total de processos no estado executável, e o número toal de processos em “uninterruptable task state”. Um processo em um estado executável ou está usando a CPU ou esperando para usar a CPU (na fila de processos executáveis). Um processo está no estado não susceptível de interrupção quando está esperando por algum tipo de acesso I/O, por exemplo, à espera de disco. As médias são tomadas ao longo dos três intervalos de tempo.
b) Médias de carga não são normalizadas para o número de CPUs em um sistema: uma média de carga 1 significa que em um sistema com processador único este está carregado todo o tempo, enquanto que em um sistema de 4 CPUs significa que a CPU está ativa por 25% do tempo.
Como saber o número de CPUs? Basta usar o comando “top”, e quando este estiver em execução digital a tecla “1”. Então para o caso de 8 CPUs, temos para o load average acima: 1,15/8 => 14,4% de tempo de CPU ativa.
ps: relatório instantâneo dos processos atuais.
top: um “ps” repetitivo
Ferramentas como o ‘ps’ e ‘top’ relatam vários tipos de usos de memória, tais como o tamanho da VM e o “Resident Set Size (RSS)”. No entanto, nenhum deles informa realmente o uso da memória “real”:
- o código do programa é compartilhado entre várias instâncias do mesmo programa;
- o código das bibliotecas é compartilhado entre todos os processos que utilizam essa biblioteca;
- alguns “apps fork” dos processos compartilham memória com eles (por exemplo, através de segmentos de memória compartilhada).
- RSS é 0 quando um processo é trocado, o que não é muito útil.
- o valor do RSS não inclui a memória compartilhada. Devido ao fato que a memória compartilhada não ser pertencente a apenas 1 processo, “top” não inclui seu valor no RSS. Então, isto causa o número indicativo de “free” ser maior que a soma em “top” do RSS.
- etc.
Exemplos:
# ps aux
# ps -ef
# ps -eF
# ps -ely
# ps -u www-data
# ps -e -o pid,args --forestO exemplo acima apresenta os processos e comandos em uma forma hierárquica. O argumento “–forest” é que força a exibição da árvore de processos. A partir desta árvore, podemos identificar qual é o processo pai e os processos filhos que bifurcam de forma recursiva.# top
# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.0 10644 820 ? Ss Out21 0:03 init [2]
root 382 0.0 0.0 21508 1392 ? Ss Out21 0:00 udevd --daemon
root 409 0.0 0.0 71188 3704 ? Ss 17:10 0:00 sshd: root@notty
root 469 0.0 0.0 12668 992 ? Ss 17:10 0:00 /usr/lib/openssh/sftp-server
root 537 0.0 0.0 21504 1048 ? S Out21 0:00 udevd --daemon
5003 2336 0.0 0.1 313348 17712 ? Ss 11:21 0:00 /usr/bin/php-cgi -d magic_quotes_gpc=off -d session.save_path=/usr/local/ispconfig/server/temp
5003 2338 0.0 0.1 319144 19580 ? S 11:21 0:00 /usr/bin/php-cgi -d magic_quotes_gpc=off -d session.save_path=/usr/local/ispconfig/server/temp
postfix 4906 0.0 0.0 71904 4108 ? S 21:03 0:00 smtp -t unix -u -c
postfix 4907 0.0 0.0 71904 4144 ? S 21:03 0:00 smtp -t unix -u -c
postfix 4909 0.0 0.0 39888 2372 ? S 21:03 0:00 bounce -z -n defer -t unix -u -c
root 5555 0.0 0.0 23156 2864 ? S 18:46 0:00 dovecot/config
www-data 5669 0.0 0.0 395552 16304 ? S 11:24 0:14 /usr/sbin/apache2 -k start
www-data 5686 0.0 0.0 395420 16440 ? S 11:24 0:14 /usr/sbin/apache2 -k start
www-data 5687 0.0 0.1 398276 22120 ? S 11:24 0:14 /usr/sbin/apache2 -k start
postfix 6181 0.0 0.0 39888 2372 ? S 21:04 0:00 bounce -z -n defer -t unix -u -c
postfix 6695 0.0 0.0 39988 2408 ? S 21:05 0:00 showq -t unix -u -c
110 7227 0.0 0.0 29800 460 ? Ss Out21 0:00 /usr/bin/dbus-daemon --system
root 17621 0.0 0.0 21644 1004 ? Ss Out22 0:06 /usr/sbin/dovecot -c /etc/dovecot/dovecot.conf
dovecot 17631 0.0 0.0 13044 1044 ? S Out22 0:01 dovecot/anvil
root 17632 0.0 0.0 13172 1296 ? S Out22 0:01 dovecot/log
root 18009 0.0 0.0 45480 2872 ? S Out22 0:02 dovecot/auth
root 20748 0.0 0.0 19168 1412 ? S Out23 0:00 dovecot/ssl-params
amavis 22761 0.0 0.5 223636 96088 ? Ss Out21 0:05 /usr/sbin/amavisd-new (master)
root 23359 0.0 0.0 49848 1244 ? Ss Out22 0:02 /usr/sbin/sshd
root 23419 0.9 0.0 500192 10624 ? Sl Out22 39:03 /usr/bin/python /usr/bin/fail2ban-server -b -s /var/run/fail2ban/fail2ban.sock
clamav 23501 0.0 1.4 378096 238528 ? Ssl Out21 3:00 /usr/sbin/clamd
clamav 30828 0.0 0.0 43372 2200 ? Ss Out21 5:00 /usr/bin/freshclam -d --quiet
VSZ – virtual set size (em KB, quanto de memória o processo estaria utilizando se ele fosse o único processo rodando, sem utilizar bibliotecas compartilhadas).
RSS – resident set size (em kB, indica – em tese – a quantidade de memória física que o processo está usando)
2.5 Ferramenta nmon
nmon é um administrador de sistemas, sintonizador, ferramenta de benchmark. Ele pode exibir o CPU, memória, rede, discos (mini gráficos ou números), sistemas de arquivos, NFS, os processos principais, recursos (versão do Linux e processadores) e outras informações. Ao iniciar o aplicativo, este fica esperando comandos do usuário, cuja lista pode ser visualizada através da telca “h”. Veja a ilustração abaixo:

3. Analisando a utilização da memória
O Linux gerencia a memória em unidades chamadas páginas. O tamanho atual de uma página de memória no PC é de 4K. O kernel do Linux aloca páginas virtuais para processos à medida que eles forem solicitando memória. O Linux pode alocar efetivamente tanta memória quanto os processos solicitarem amplicando a RAM real com espaço de swap.
Basicamente, três números quantificam a atividade de memória:
- a quantidade total de memória virtual ativa;
- taxa de swapping;
- taxa de paginação.
3.1 Indo direto a fonte de informação
# cat /proc/meminfo
MemTotal: 16471012 kB
MemFree: 11282704 kB
Buffers: 270516 kB
Cached: 3398320 kB
SwapCached: 0 kB
Active: 3457056 kB
Inactive: 1120516 kB
Active(anon): 908908 kB
Inactive(anon): 17796 kB
Active(file): 2548148 kB
Inactive(file): 1102720 kB
Unevictable: 0 kB
Mlocked: 0 kB
SwapTotal: 29642748 kB
SwapFree: 29642748 kB
Dirty: 1312 kB
Writeback: 0 kB
AnonPages: 909216 kB
Mapped: 59120 kB
Shmem: 17972 kB
Slab: 463492 kB
SReclaimable: 412220 kB
SUnreclaim: 51272 kB
KernelStack: 2888 kB
PageTables: 83564 kB
NFS_Unstable: 0 kB
Bounce: 0 kB
WritebackTmp: 0 kB
CommitLimit: 37878252 kB
Committed_AS: 4737592 kB
VmallocTotal: 34359738367 kB
VmallocUsed: 59772 kB
VmallocChunk: 34359669008 kB
HardwareCorrupted: 0 kB
AnonHugePages: 0 kB
HugePages_Total: 0
HugePages_Free: 0
HugePages_Rsvd: 0
HugePages_Surp: 0
Hugepagesize: 2048 kB
DirectMap4k: 89408 kB
DirectMap2M: 16687104 kB
Mostra a quantidade total de memória livre e utilizada no sistema, tanto a memória física como a de swap, bem como os buffers utilizados pelo kernel. A coluna de memória compartilhada (“shared memory”) deve ser ignorado, está obsoleta.
Exemplos:
# free
# free -t
# free -m
# free -h
# free -s 3 -c 10
# free -t
total used free shared buffers cached
Mem: 16471012 2871416 13599596 0 118556 1512528
-/+ buffers/cache: 1240332 15230680
Swap: 29642748 0 29642748
Total: 46113760 2871416 43242344
Mostra o sumário do uso de swap por “device”.
# swapon -s
Filename Type Size Used Priority
/dev/mapper/server01-swap_1 partition 29642748 0 -1
Mostra estatisticas do sistema a partir de /proc. Algumas das informações na saíde de procinfo sobrepõem aquelas de free, uptime e vmstat.
Exemplos:
# procinfo
# procinfo -n5
# procinfo -d# procinfo
Memory: Total Used Free Buffers
RAM: 16471012 2887212 13583800 118900
Swap: 29642748 0 29642748
Bootup: Mon Oct 21 06:13:43 2013 Load average: 0.92 1.22 1.33 3/330 26091
user : 3d 00:46:47.07 8.2% page in : 1737489
nice : 00:00:15.38 0.0% page out: 64158644
system: 1d 05:13:04.66 3.3% page act: 5530057
IOwait: 02:12:10.39 0.2% page dea: 622
hw irq: 00:00:00.02 0.0% page flt: 21189714766
sw irq: 00:12:55.88 0.0% swap in : 0
idle : 4w 4d 15:06:37.00 88.2% swap out: 0
uptime: 4d 15:05:08.70 context : 740995265
irq 0: 1377 timer irq 15: 359 ata_piix
irq 1: 3 i8042 irq 16: 0 uhci_hcd:usb5
irq 6: 3 floppy irq 17: 22 ehci_hcd:usb1, uh
irq 8: 1 rtc0 irq 18: 0 uhci_hcd:usb4
irq 9: 0 acpi irq 19: 0 uhci_hcd:usb3
irq 12: 5 i8042 irq 65: 45100644 eth0
irq 14: 2498028 ata_piix irq 67: 4 ioat-msi
sda 88800r 2281754w dm-0 114634r 5913904w
sdb 355r 0w dm-1 127r 0w
eth0 TX 31.08GiB RX 11.59GiB lo TX 230.16MiB RX 230.16MiB
eth1 TX 0.00B RX 0.00B
a) sobre o load average:
3/330 – existem 330 processos no total
26091 – último processo a ser executado tinha PID 26091
b) context – número de trocas de contexto, desde a inicialização.
c) page in – número de blocos do disco paginada do disco na RAM. Um bloco é igual a 1 KB.
d) page out – número de blocos de disco paginada da RAM para o disco. Isso inclui a escrita regular no disco.
e) Interrupções – número de interrupções desde o boot, ou por intervalo, listado por IRQ.
4. Analisando o I/O de disco
4.1 Ferramenta iostat
Relatório com estatísticas da CPU e de entrada/saída de dispositivos e partições. Usado para monitorar o sistema de carga de entrada/saída de dispositivos, observando o tempo que os dispositivos estão ativos em relação às suas taxas de transferências médias.
Exemplos:
# iostat -t (mostrar um único relatório, com a primeira linha "avg-cpu" representa estatisticas desde o último boot).
# iostat 4 ( executar iostat automaticamente a cada 2 segundos - até o usuário pressionar Ctl-C)
# iostat -x (mostrar estatisticas estendidas)
# iostat -d 2 (mostrar continuadamente o relatório de "devices" com intervalos de 2 segundos).
# iostat -d 2 6 (mostrar 6 relatórios com 2 segundos de intervalo para todos os "devices")Algumas explicações:# iostat -t Linux 3.2.0-4-amd64 (server01.meusitio.org) 25-10-2013 _x86_64_ (8 CPU) 25-10-2013 21:35:50 avg-cpu: %user %nice %system %iowait %steal %idle 8,21 0,00 3,32 0,25 0,00 88,22Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn sda 5,93 4,34 160,34 1738112 64284836 sdb 0,00 0,00 0,00 1349 0 dm-0 15,07 4,33 160,34 1734281 64284828 dm-1 0,00 0,00 0,00 508 0
a) tps – transações totais por segundos, que é a soma do número de transações de leitura por segundo com o número de transações de escrita por segundo.
b) kB_read/s – quantidade de dados lidos a partir do dispositivo, expressa em número de blocos (kilobytes) por segundo. Blocos são equivalentes aos setores e, portanto, têm um tamanho de 512 bytes. OBS: é a mesma informação dada em “IO – bi” da ferramenta vmstat.
c) kB_wrtn/s – quantidade de dados gravados no dispositivo expresso em número de blocos (kilobytes) por segundo. OBS: é a mesma informação dada em “IO – bo” da ferramenta vmstat.
d) kB_read – o total número de blocos (kilobytes) lidos.
e) kB_wrtn – o total número de blocos (kilobytes) escritos.
5. Análise de I/O de rede
5.1 Ferramenta IPTraf
IPTraf é um monitor de LAN IP que gera várias estatísticas de rede, incluindo informações TCP, contagens UDP, informações ICMP e OSPF, informações de carga Ethernet, estatísticas do “node”, erros de checksum IP entre outros. O aplicativo pode funcionar no modo interativo ou em background. Se o comando iptraf é emitido sem o parâmetro “-B” na sua linha de comando, o programa inicia no modo interativo, com as diversas facilidades acessados através do menu principal.
A forma mais simples de iniciar o aplicativo no modo interativo, basta usar o comando sem qualquer parâmetro:
# iptrafPara o modo em background, é importante fazer previamente a configuração do IPTraf através do modo interativo, e só após isto iniciar a sessão de aquisição estatistica em background. Configure o aplicativo da maneira usual (definir os filtros, logs, intervalos de aquisição, adicionar as portas TCP/UDP, etc). Uma vez feito a configuração, elimine todas as instâncias do IPTraf que possam existir no sistema, e invoque o IPTraf da linha de comando com os parâmetros desejados, não esquecendo obrigatoriamente do parâmetro “-B” para criar o programa daemon.
Exemplos de comandos para IPTraf em background:
a) Monitorar o tráfego IP para a interface eth0, durante 3 minutos:
# iptraf -i eth0 -t 3 -Bobs: cuidado, o arquivo de log poderá crescer muito se o tempo de coleta for grande!
b) Coletar estatísticas detalhadas da interface eth0, durante 5 minutos:
# iptraf -d eth0 -t 5 -Bc) Coletar estatísticas sobre os serviços que estão sendo utilizados pela interface eth0, durante 2 minutos:
# iptraf -s eth0 -t 2 -BObs:
- A saída de logs do aplicativo está na pasta /var/log/iptraf/
- O parâmetro -B automaticamente habilita o log independentemente do que está configurado no aplicativo.
- Para especificar nomes personalizados para os arquivos de logs, adicione na linha de comando o parâmetro -L. Se este parâmetro não for especificado, o nome default do arquivo de log para a facilidade será usado. Se o usuário não especificar o caminho, o arquivo de log será colocado no local padrão em /var/log/iptraf.
- Toda vez que iniciar em background o IPTraf, verifique se o processo realmente está em execução da seguinte forma:
# ps -A | grep iptraf
28380 ? 00:00:00 iptraf - Se desejar abortar um processo em execução do IPTraf, utilize o comando:
# kill -USR2 , onde o pid é obtido facilmente com o comando:# ps -A | grep iptraf
Obs:
i) ao interromper desta forma a execução do IPTraf, os resultados parciais serão depositados no arquivo de log;
ii) nunca utilize o comando # killall -9 iptraf para abortar um processo do IPTraf, pois isto resultará em uma saída com erro e bloqueará recursos no sistema. Ou seja, caso seja ocasionalmente utilizado este comando, a interface ficará presa e bloqueará o início de um novo processo do IPTraf. No modo interativo, serão emitidas mensagens de erro do tipo: “Detailed interface stats already monitoring eth0” ou ainda “IP Traffic Monitor already listening on eth0”. Para sair desta situaçao, faça o seguinte:# iptraf -f
Este comando irá resetar os sockets, apagar todos os bloqueios e contadores, e assim deixar livres as interfaces para poderem ser lidas novamente. Uma forma alternativa a este comando é removendo diretamente os arquivos do status/controle do aplicativo:# rm /var/run/iptraf/* -rf - IPTraf programado através do CRON: pode ser interessante programar o IPTraf para rodar de tempos em tempos automaticamente. Para isto, como administrador, edite a tabela do cron através do comando “
crontab -e” e insira a linha:*/30 * * * * /usr/sbin/iptraf -s eth0 -t 2 -B
Isso fará com que a cada 30min o IPTraf seja acordado e colete durante 2min estatísticas sobre os serviços que estão sendo utilizados pela interface eth0. Isto é um exemplo, pois as opções de funcionamento do IPTraf são várias, conforme viamos acima. O relatório cumulativo ao longo do tempo estará disponível na pasta /var/log/iptraf/
Fonte: https://concani3.wordpress.com/2013/10/27/analise-de-desempenho-de-uma-maquina-linux-com-debian/
Nenhum comentário:
Postar um comentário
Observação: somente um membro deste blog pode postar um comentário.